While working on a data and building a learning model, its very important to know that how complicated is the model. Will it perform accurately on new data elements. Vapnik-Chervonenkis showed that the capacity of the model can be calculated before. They gave a new concept of VC dimension which can predict upper bound on the test error of a classification model. Vapnik showed that

where h is the VC dimension of the classification model and N is the size of the training dataset. Now the problem is that for a given model how do we define and find h, the VC dimension. Lets see.
Lets first get idea about indicator function, 






As we can see, the three points are separated in all 

The first figure shows three co-linear points which cannot be separated by an indicator function
From above relation we can see that VC dimension increases as the number of weight vector parameters increases. But this doesn’t mean that learning machine with many parameters will have a high VC dimension and so on. For example 
Why VC dimension?
Suppose you want to classify a data. Now what do you do? One way is that you try every possible classifier, a line, a plane or hyperplane until you get the best. The other way is that you already know a function that can separate(may be not correctly as discussed above) the data. So you use that function as your hypothesis which can minimize the test error.
Structural Risk minimization
SRM is basically choosing a hypothesis of right complexity from a large number of possible hypothesis, for training data elements which can be done by restricting the hypothesis space H of approximating functions. These learning machines will form a nested structure as following:
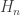


 The complex term inside the bracket is called a VC Confidence or Confidence Interval. The above equation shows that when the number of training data increases,
The complex term inside the bracket is called a VC Confidence or Confidence Interval. The above equation shows that when the number of training data increases, 
At this point, it should be clear how SRM works – it uses VC dimension as a controlling parameter for minimization of generalization bound(test error). There are basically two approaches while designing statistical learning from data models that is two ways to minimize the right-hand side term.
- Choose appropriate structure and keeping the confidence interval fixed, minimize the training error.
- Keeping the value of the training error fixed, minimize the confidence interval.
Neural Networks uses first approach while Support Vector Machines implements second strategy.
The last post about Data and now this one is the basic idea needed in statistical learning which is worth learning when dealing with Machine Learning. It is for sure gonna help while understanding other approaches and techniques. Keep Learning.
